La nécessité de mesures plus nombreuses
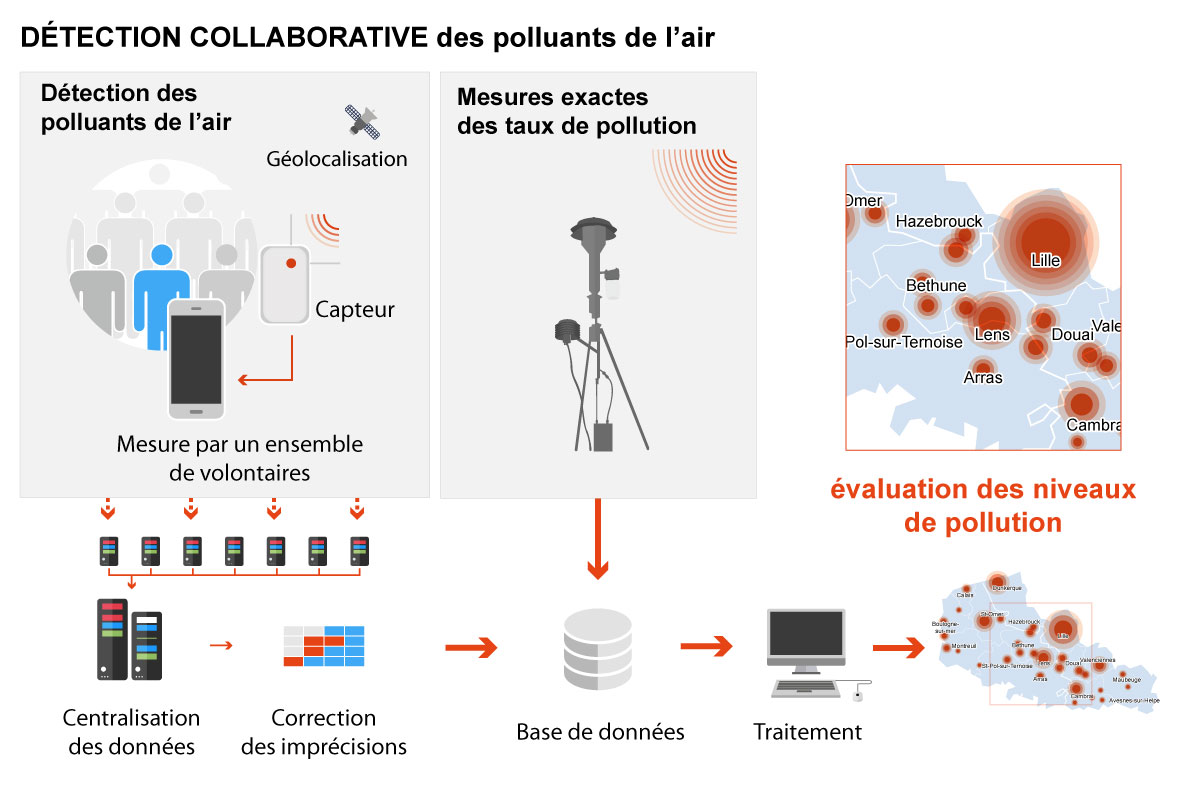
Face à la multiplication des pics de pollution ces derniers mois, la nécessité d'évaluer en temps réel la qualité de l'air, mesurée à partir de la concentration de différents éléments dont les plus nocifs, s'impose toujours davantage. Les informations recueillies par des organismes régionaux, comme airparif en Île-de-France, ou atmo dans les Hauts-de-France, proviennent de capteurs spatialement trop éloignés et aux fréquences de mesure trop espacées pour rapidement des phénomènes très localisés présentant un risque pour la santé. À cause de cela, les prévisions sur les évolutions des concentrations en polluants se révèlent généralement imprécises à une échelle fine. Dans la région des Hauts-de-France, un consortium de laboratoires de recherche (LISIC de l'ULCO, Spirals de l'INRIA), d'associations (ATMO Hauts de France, Association BES) et d'organismes régionaux (lycées, universités partenaires de BES) a décidé de s'attaquer à ce problème. De là est né le projet oscar. Son principe est de faire participer la population à l'évaluation de la qualité de l'air.
Des boîtiers connectés pour l'acquisition des données
L'idée de cette initiative consiste à équiper des volontaires de boîtiers d'acquisition constitués de capteurs miniaturisés mesurant la concentration de différents polluants dans l'atmosphère environnante et partager ces données via leurs de smartphones.
Les capteurs légers et peu encombrants se connectent par exemple via Bluetooth, à un smartphone ou à une tablette numérique. Cette solution économique permet de faire appel aux étudiants des lycées techniques et iut de la région, managés par leurs enseignants et les membres de l'association BES, pour assembler les boîtiers avec des capteurs du commerce, selon un modèle fourni par un laboratoire de la région, le LISIC.
Grâce à eux, la diffusion d'une masse critique de boîtiers fonctionnels est assurée. Les données obtenues par crowd-sensing mobile, c'est-à-dire via les équipements connectés des particuliers serviront à établir une carte extrêmement précise de la qualité de l'air. Mais, avant d'en arriver là, de nombreux obstacles doivent être surmontés.
Étalonnage et géolocalisation
Pour tracer une carte de pollution, il faut disposer simultanément de données sur la qualité de l'air suffisamment précises et d'un positionnement exact du lieu où a été prise chaque mesure. On voit là l'intérêt d'utiliser des appareils mobiles comme les smartphones : ils sont équipés de gps, ce qui permet de transmettre en même temps les données sur la qualité de l'air et la localisation du mobile.
Mais plusieurs problèmes se posent alors. Comment garantir que les informations de géolocalisation sont suffisamment précises pour certifier l'exactitude du rendu final ? Et cette étape de positionnement des différents appareils est loin d'être la contrainte principale. Rien ne permet en effet d'affirmer a priori que deux appareils, situés au même endroit, enregistreront les mêmes valeurs. On appelle étalonnage des capteurs la phase de réglages permettant d'assurer ce dernier point. Or, il est impossible de réaliser cette calibration au cours de la fabrication des composants, en raison du mode de fabrication retenu. On doit donc l'effectuer a posteriori, à distance et sans avoir un contrôle total sur l'environnement d'utilisation du capteur, c'est pourquoi on parle d'étalonnage aveugle. Le LISIC a développé une approche originale d'étalonnage aveugle qui présente de nombreuses similarités avec des problématiques en intelligence artificielle.
Focus sur le problème de Netflix
La réalisation de cette étape est analogue, d'un point de vue mathématique, à ce qui est connu comme le problème de Netflix, du nom du fameux site internet répertoriant des films et des séries. L'idée est de trouver un moyen de proposer les meilleures recommandations de film à un utilisateur donné. Pour cela, Netflix disposait initialement d'évaluations de 17 770 films par 480 189 internautes, chaque évaluation correspondant à l'attribution d'un nombre de 1 à 5. Or, chaque utilisateur n'a noté qu'un tout petit nombre de films : au départ, on ne connaissait que 100 480 507 évaluations parmi plus de 8 milliards possibles. Le problème consistait donc à compléter une matrice de taille 480 189 × 17 770 dont on connaissait seulement moins de 1% des valeurs, qui correspondent aux évaluations connues. La complétion de cette matrice était possible si on supposait que les goûts de tout utilisateur pouvaient être vus comme un „mélange“ de goûts très spécifiques (amateurs de films d'action, comédie romantique, etc). Mathématiquement, on veut donc compléter une matrice C que l'on veut écrire sous forme approximée Ĉ comme le produit de deux matrices U et F; U contenant un ensemble de profils d'utilisateurs typiques et F contenant une matrice de poids indiquant la part de mélange de ces profils typiques qui peuvent expliquer les goûts d'un utilisateur.
Pour en revenir à notre problème, les internautes sont les analogues des endroits précis où ont été effectuées les mesures et les évaluations correspondent aux données à étalonner. On veut donc construire Ĉ, dont chaque ligne correspond à une localisation et chaque colonne à un capteur à étalonner. La valeur indiquée dans une case de la matrice représentera donc la quantité mesurée par un capteur d'un élément toxique en un point parfaitement repéré.Comme pour le projet Netflix, Ĉ peut être vue comme un produit de deux matrices U et F où U contiendra notamment la concentration exacte du polluant recherché en chaque point de mesure possible, alors que F contiendra les paramètres intrinsèques d'étalonnage de chaque capteur. Bien que les outils mathématiques soient relativement similaires, les objectifs du problème de Netflix et du projet OSCAR sont donc différents, puisque le premier s'intéresse à Ĉ alors que les matrices U et F sont importantes pour respectivement mesurer des cartes de pollution ou réaliser l'étalonnage des capteurs dans le projet OSCAR.
Ce problème de complétion de matrices a été programmé informatiquement grâce à des algorithmes de plus en plus rapides : une implémentation de 2013 permettait de compléter en 3 secondes une matrice de taille 100 x 1000 avec une précision relative de 10-5.
Des mesures à l'exploitation
Les informations obtenues par les smartphones sont transmises à une plateforme par Internet. Les données sont d'ailleurs anonymisées grâce à la plateforme apisense®, de l'INRIA, pour respecter la vie privée des volontaires. Les techniques de traitement mathématiques exposées précédemment permettent d'étalonner les capteurs au fur et à mesure que les données sont collectées.
Après ce traitement, la collection d'informations mobiles issues du crowd-sensing est intégrée avec les mesures réalisées par des stations atmosphériques du réseau atmo au sein d'une base de données.
Ce nouveau traitement permet de construire des modèles, comme des cartes géographiques, où l'on peut repérer les concentrations anormales de polluants, et découvrir presque en temps réel leurs déplacements.
Cette approche ouvre de nombreuses perspectives en matière de suivi des flux de polluants et de prévision des risques environnementaux. Une initiatie qui n'aurait jamais été réalisable sans les plus récentes avancées mathématiques et informatiques...